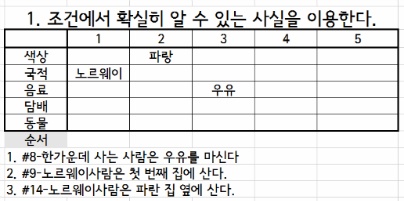
안녕하세요. 이번 포스팅에서는 전방 연쇄(Forward chaining)와 후방 연쇄(Backward chaining)에 대해서 알아보겠습니다. 1. 전방 연쇄(Forward chaining) 먼저 전방 연쇄란, 기존의 알려진 사실들로 하여금 새로운 사실을 추리하면서 나아가는 방법입니다. 이름처럼 원래 알고 있는 것을 바탕으로 앞으로 나아가는 방법이죠. 즉, 한 문장, 함의에 대한 모든 전제가 알려져 있는 사실이라면 그것에 대한 결론을 새로운 사실로써 지식기지에 추가합니다. 예를 들어, A라는 사실과 B라는 사실을 알고 있을 때, 지식기지에 A∧B=>C 가 있다면 C를 하나의 사실로써 추가할 수 있습니다.이러한 과정을 통해 알고자 하는 사실 Q에 도달하거나 더 이상 추리가 불가능 할때 까지 반복합니다.아..